UPDATE: Researchers at South China Agricultural University and Shanghai University of Finance and Economics have unveiled a groundbreaking framework that significantly enhances the mathematical reasoning capabilities of large language models (LLMs). This development, just published in the Journal of King Saud University Computer and Information Sciences, could transform how AI systems assist in education and professional environments.
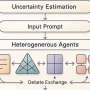
The newly introduced framework, known as A-HMAD (Adaptive Heterogeneous Multi-Agent Debate), utilizes a unique multi-agent debate system to improve the reliability of AI responses. This comes on the heels of ongoing concerns regarding the accuracy of LLMs, which have been known to produce factually incorrect or logically flawed answers despite their sophisticated capabilities.
Research indicates that LLMs often struggle with logical consistency and factual accuracy, limiting their effectiveness in educational and professional settings. The A-HMAD framework addresses these issues by allowing multiple AI agents to engage in debates, each possessing distinct areas of expertise—such as logical reasoning and factual verification—thereby enhancing the overall robustness of their conclusions.
Initially tested on six challenging benchmarks, including arithmetic QA and grade-school math, the A-HMAD framework achieved an impressive 4–6% absolute accuracy gain over previous models and reduced factual errors by over 30%. These findings underscore the potential for A-HMAD to improve the quality of AI-generated responses, making them more reliable for users who depend on accurate information.
“Prior efforts improved LLM performance using single model instances, but our approach introduces diverse roles among agents, enhancing error-checking and perspective,” stated Yan Zhou and Yanguang Chen, the researchers behind the study. They emphasized that this “society of minds” method not only boosts mathematical reasoning but also reduces the likelihood of factual hallucinations.
The consensus optimizer developed within the framework plays a critical role in evaluating the contributions of each AI agent, ensuring that the final response is both accurate and coherent. This dynamic selection of agents based on the debate’s context enables a more tailored approach to problem-solving.
Looking ahead, the implications of A-HMAD are profound. The researchers anticipate that this innovative framework could lay the groundwork for creating a more reliable AI platform for teachers, scientists, and professionals. “Our findings suggest that an adaptive, role-diverse debating ensemble can drive significant advances in LLM-based educational reasoning,” they concluded.
As this technology evolves, it holds promise for making AI systems safer, more interpretable, and pedagogically sound—key factors for their integration into everyday use in classrooms and workplaces.
Stay tuned for further updates as this story develops, revealing how A-HMAD could redefine the landscape of artificial intelligence and its applications in education and beyond.





